HW红队攻击方案
转载请注明出处:https://youngrichog.github.io/**
描述
HW行动近些年关注度持续提升,站在攻击方的角度,我们应该如何完成HW任务。对标真实战争的红方和蓝方,指挥部都会有对应的作战手册,例如:美国海军陆战队。那么回到HW中的红队,我们也应该有相应的作战手册,一个完整的作战手册可以让队伍有序战斗,可以有效提高队伍的攻击效率。因此作战手册尤为重要。
HW防守方目标众多,如何对目标进行快速的信息搜集?根据以往的渗透来说,前期的信息搜集是一个非常耗时间的工作,需要人工参与的场景比较多,那么我们就需要思考如果缩短时间,提高效率。
基础设施建设+作战手册·····
作战手册
0x01 信息搜集
前期的信息搜集涉猎点:
- 目标的母公司是什么?目标的子公司是什么?目标的对外投资有什么?
- 目标的资产有什么?网段资产/根域名/子域名是什么?
- 网段资产:网段有哪些?分别开放了什么端口/服务?目标范围是什么?哪些是Web资产?
- 根域名资产:根域名有哪些?如何快速搜集目标根域名?
- 子域名资产:子域名有哪些?子域名是否有其他端口映射(http://www.example.com:6000)?
这里可以生成对应关系:
母公司->根域名->子域名->网段资产/根域名资产/子域名资产
子公司->根域名->子域名->网段资产/根域名资产/子域名资产
目前我们已经清楚了任务,那么下一步就是思考快速完成任务,提高效率。
:bulb:子母投(母公司/子公司/对外投资)的信息搜集,我们可以借助天眼查API快速完成,这里需要关注几个点。
以下公司仅为视图案例,请勿对号入座 :-)
为保证信息搜集数据的准确,仅拉取对外投资比例=100%,以投资角度来看,这样拉取是不合适的,但在后面会以其他方式补充该数据。
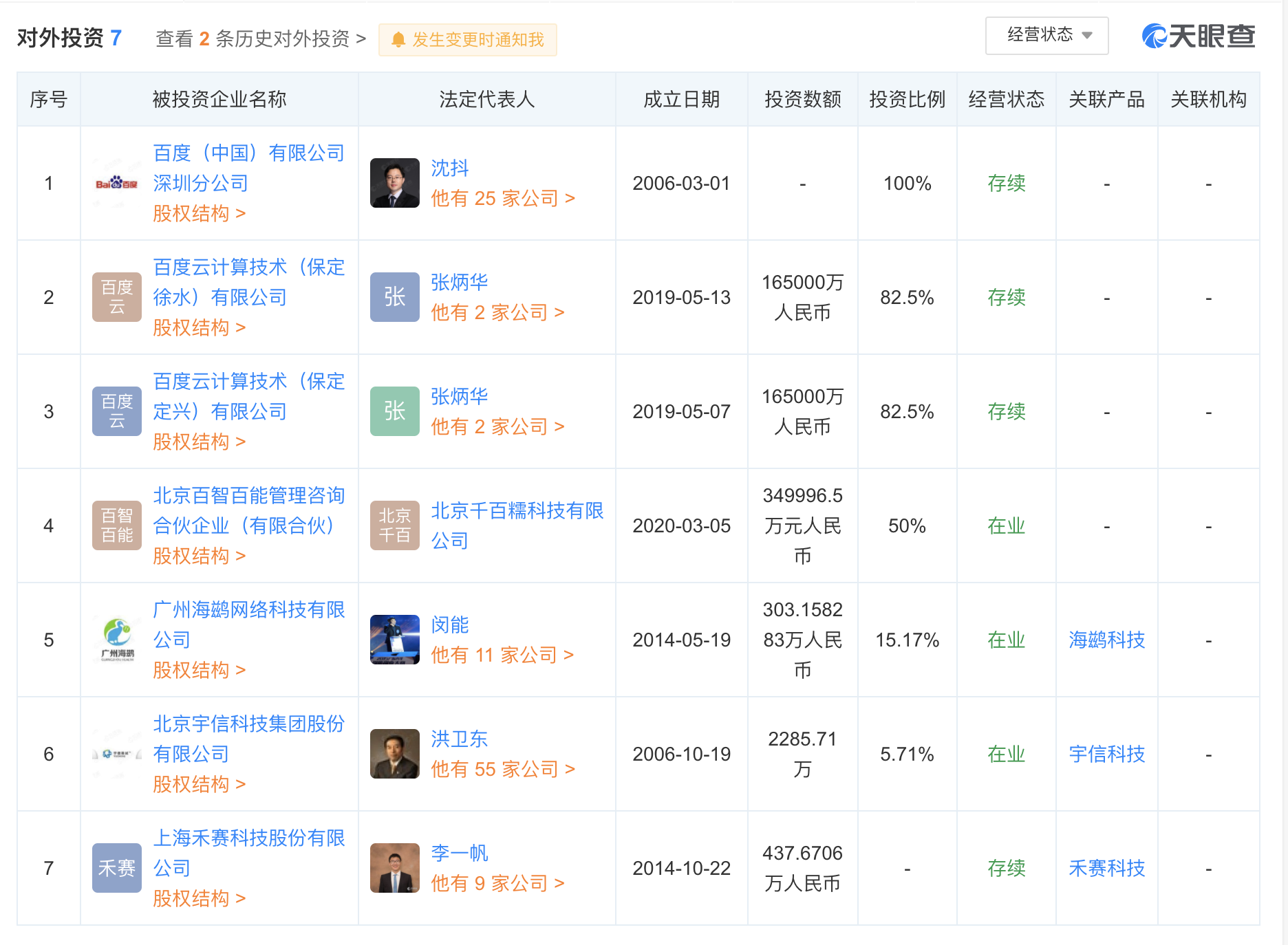
:bulb:在拥有子母投信息后,我们需要搜集子母投的根域名,这里我们同样可以借助天眼查API以及WhoisSubdomain快速完成,这里关注以下几个点。
企业介绍
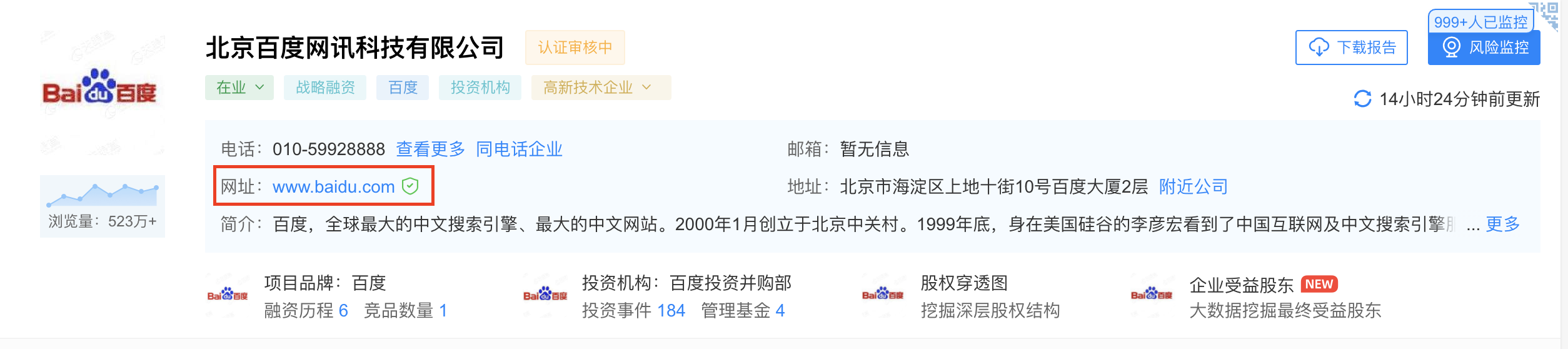
网站备案/历史网站备案
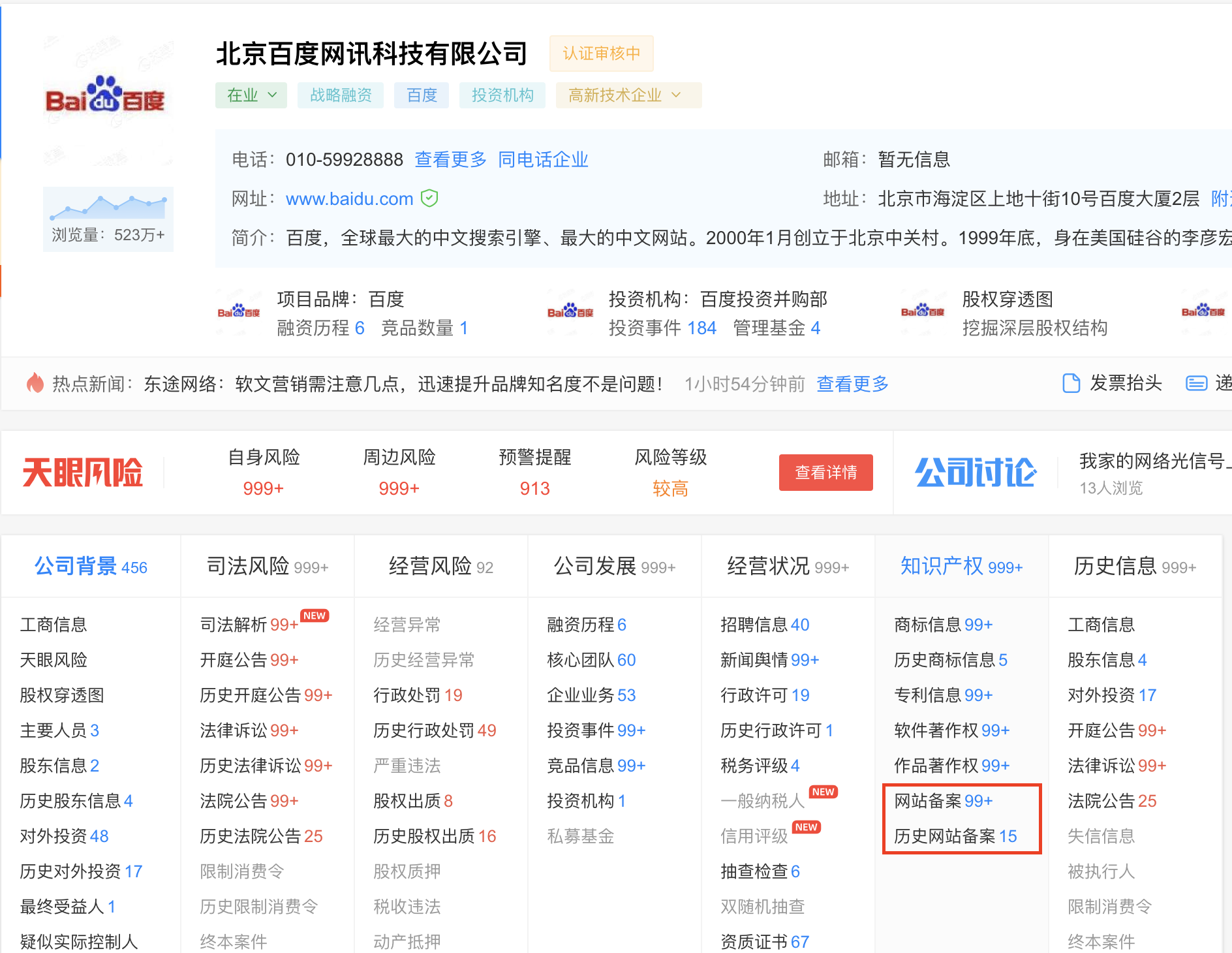
知识产权模糊查询,天眼查没有对应API接口,不过该点尤为重要。通过知识产权模糊查询,可以关联到很多与目标相关的根域名,至于如何精确,可以遍历子母投公司名称,此外公司都有简称,如北京百度网讯科技有限公司,我们可以取百度网讯科技/百度网讯作为关键字。
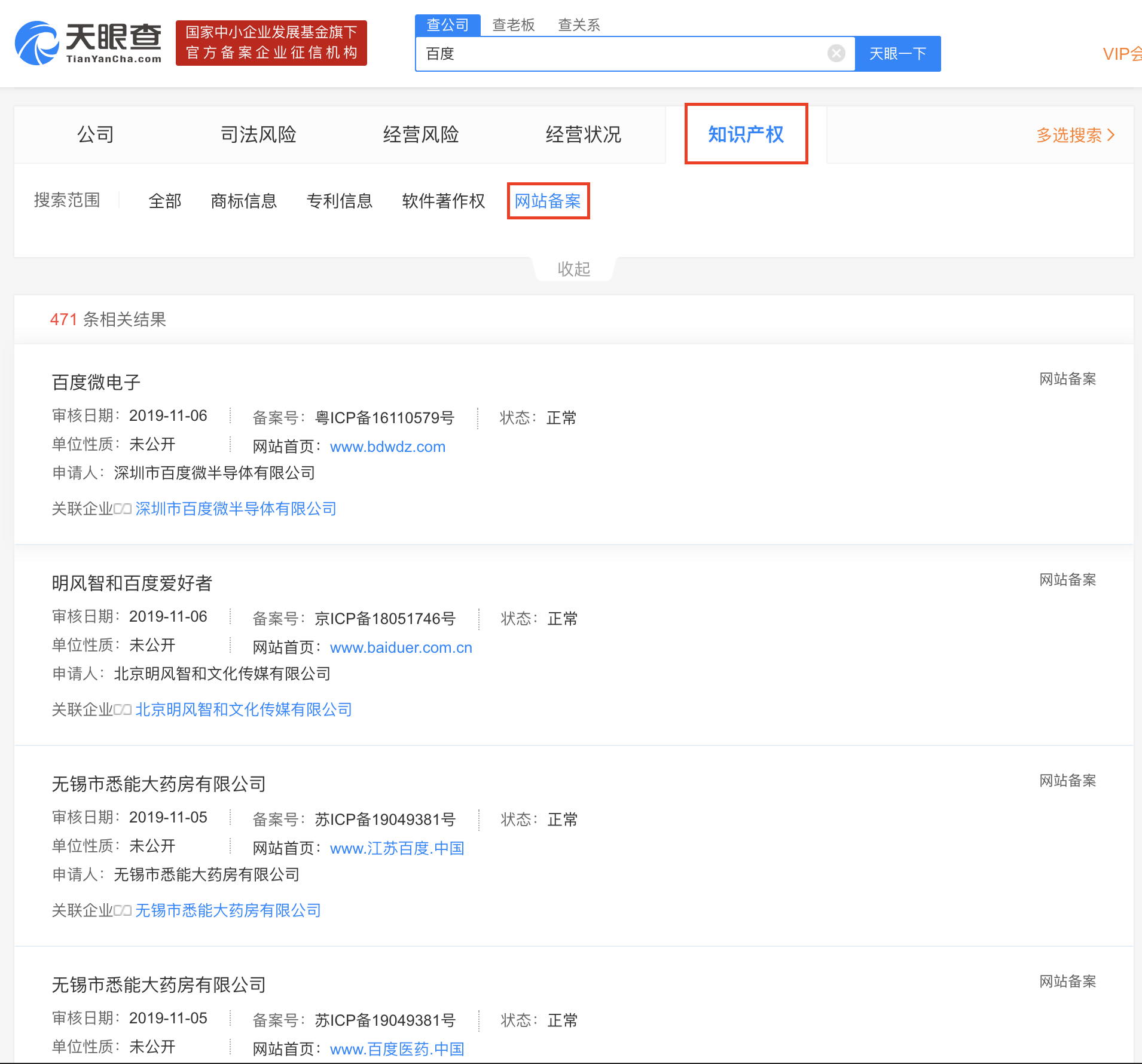
WhoisSubdomain为此而生,通过注册联系人反查、注册邮箱反查、注册联系人邮箱反查、ICP备案号反查拉出目标根域名,并补充子母投(母公司/子公司/对外投资)信息搜集阶段可能遗漏的目标。
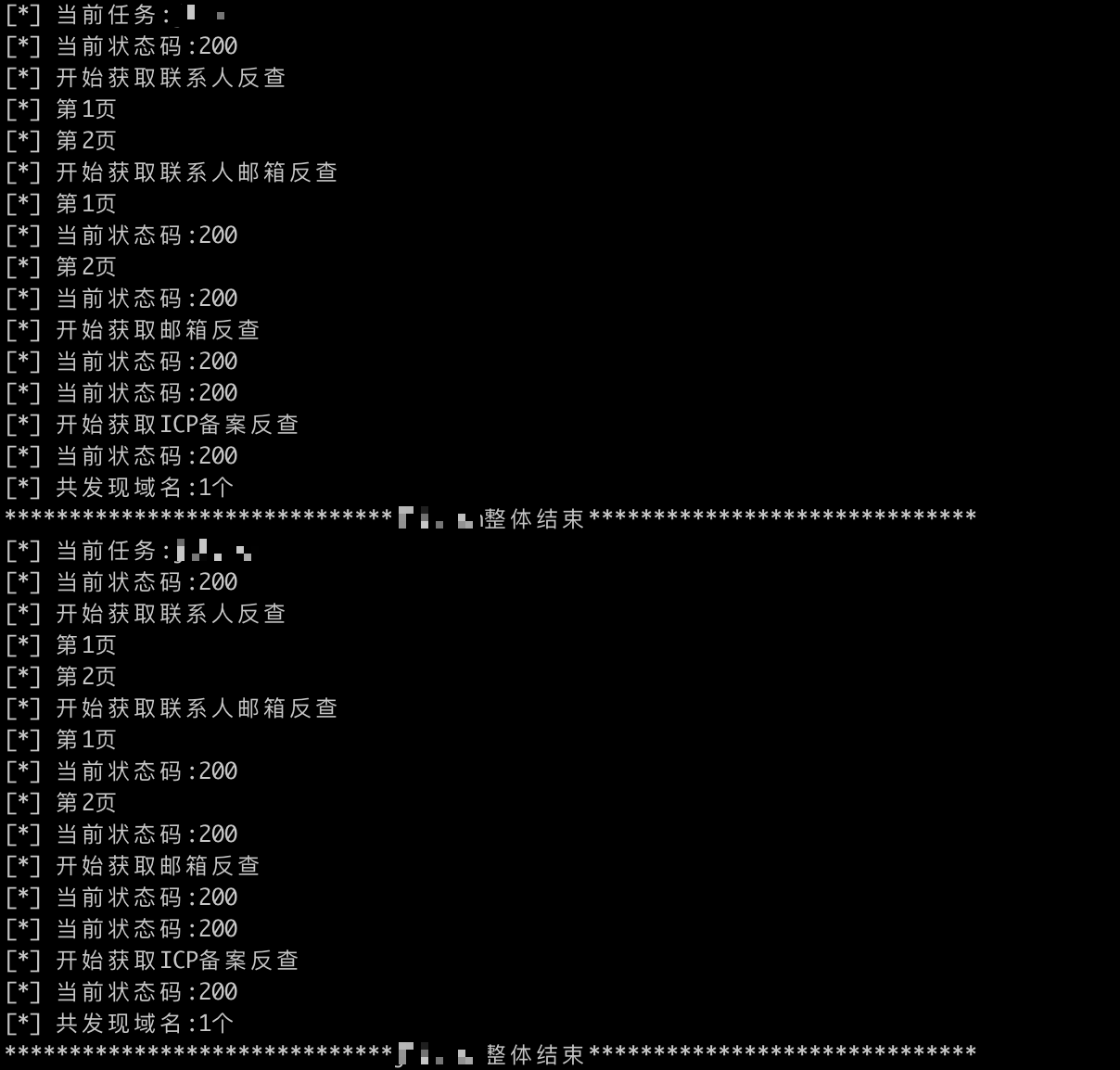
:bulb: 在拥有根域名信息后,我们需要搜集其所有根域名的子域名,这里就不多做介绍了,不过想给自己留几个坑,子域名搜集依靠穷举和第三方API,当然还有很多new school的方式,例如:爬js对其分析,域名相似(如example.com,那么example-app.com会不会是目标)等,域名相似也补充之前根域名搜集的不足。另外借助目标网段资产的端口/服务数据,我们可以通过SSL证书快速确定目标范围,哪些ip是目标的。
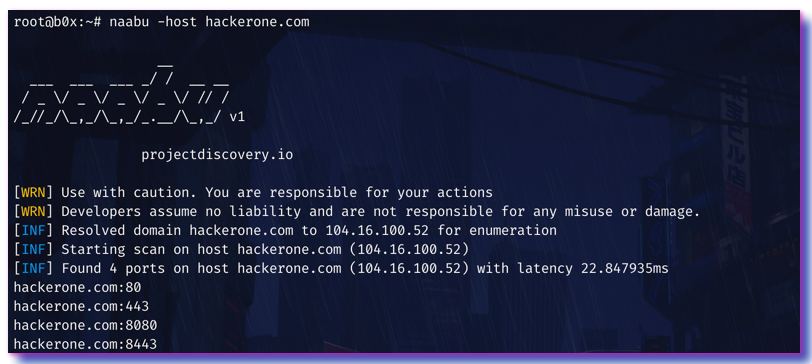
在观察中发现其实轮子早已有人造好,但是多数人都把时间浪费在重复造轮。接下来就是子域名是否有其他端口映射,很多时候我们仅关注IP的开放情况,通过naabu我们可以快速进行对应的信息搜集。
1 | cat 子域名 | ./naabu -ports full -o output.txt -v -retries 3 -rate 10 |
:bulb: 在拥有子域名信息后,我们需要搜集其网段,我们对所有子域名进行解析,这里需要进行一定方式的清洗,如使用WAF、CDN情况,这里简单举例一些方式,如通过CNAME判定,通过搜集WAF、CDN厂商IP段进行判定,通过header头中的字段进行判定,还有更多的方式后续慢慢写进来。
通过上述action后,我们拥有目标的网段资产,那么如何判定目标范围?这里简单举例:通过网段资产的端口扫描+SSL证书提取,可以从SSL证书维度确定一些目标IP,对目标IP进行大小排序,可以确定最大值和最小值从而生成目标范围。接下来就是探测开放端口/服务情况,这里提供一个之前写的Masscan+Nmap例子,在简单分布式Masscan+Nmap中也有一个例子。其中需要注意几个点:Masscan和Nmap的特征需要剔除,对于ip开启端口超过50进行剔除。
1 | #! /usr/bin/env python3 |
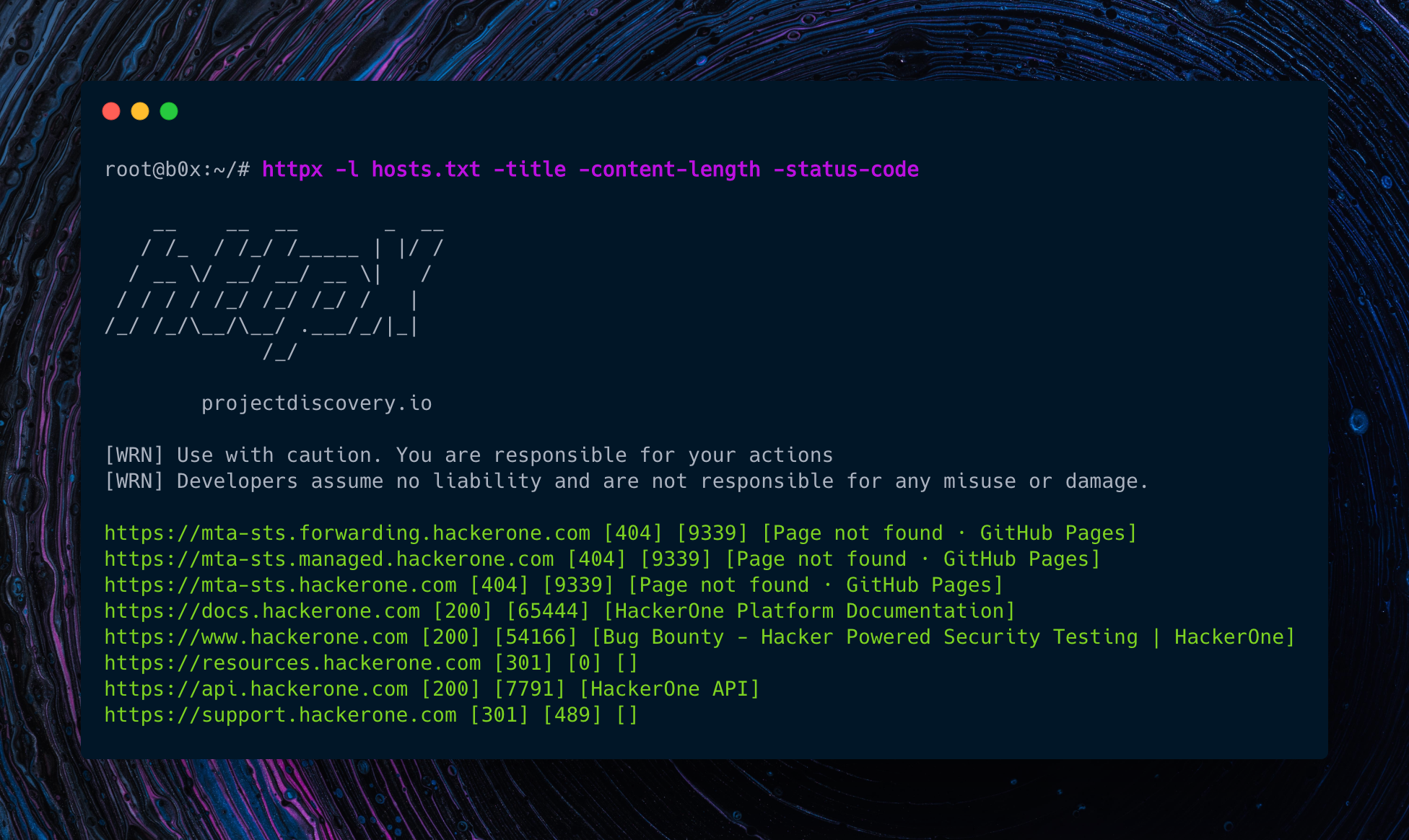
通过对网段的端口/服务扫描,我们会得到其目标的IP端口列表,接下来需要快速确定Web资产,借助httpx我们可以快速信息搜集,使用上述代码,网段资产扫描后会生成res.txt,我们加以利用,一条命令快速完成。
之前有子域名其他端口映射情况,也可以直接复用 :-)
1 | awk -F ';' '{print $1":"$5}' res.txt | sed 's/host:port//' | sed '/^\s*$/d' | ./httpx -status-code -title -web-server |
:bulb: 有些时候我们还会有网站截图的需求,通过网段资产扫描后会生成对应的.xml,借助aquatone可快速导入Masscan/Nmap数据。
1 | cat *.xml | aquatone -nmap |
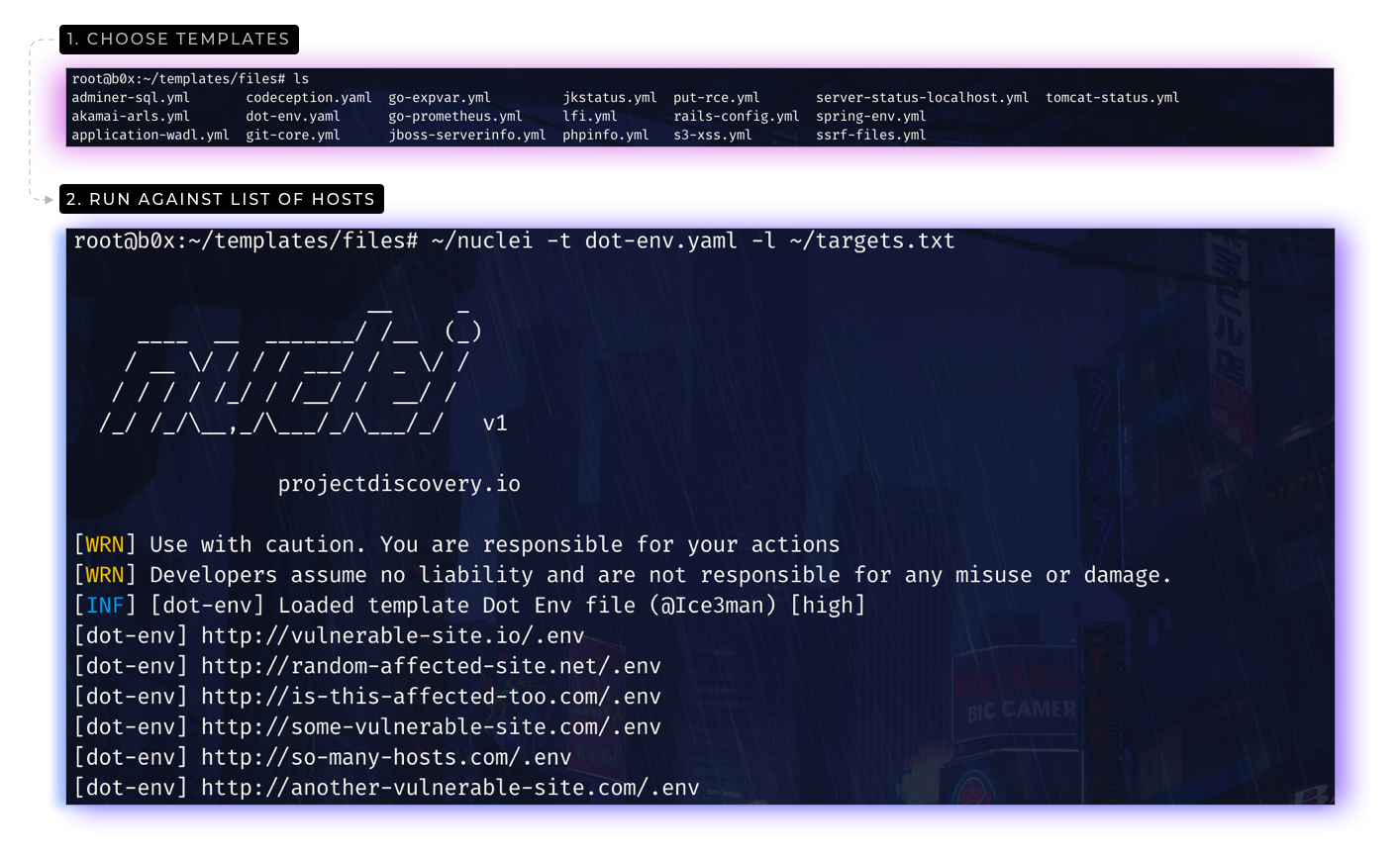
:bulb:敏感信息泄漏占比很高,如源码备份/数据库备份/git/svn等,人的错误是无法避免的,那么我们直接使用网段资产数据/子域名数据进行批量,这里借助nuclei,内置了很多插件,方便后续继续拓展。
:bulb:后续我们接入分布式的扫描器,这部分不多做介绍 :-)
到此信息搜集阶段作战结束,简单梳理下流程:
网段资产->Masscan+Nmap->httpx->nuclei
子域名资产->naabu->httpx->nuclei
有时间在把完整的流程完善 :-)
不定期更新,本次更新时间:2021年2月6日
这里延伸一个点“发现自域名最大化”,如何尽可能多的发现子域名?对于真正的黑客而言,字典是首选,其次就是第三方公司数据。
如何组成字典?字典数据的构成要从那些点出发?要从主动和被动两个方向出发,主动搜集可以从:英文单词字典、工具内嵌字典、结合大数据(例如从github爬取)等,被动搜集可以从日常积累中,例如Domain Hunter就是一个不错的被动搜集,当然还可以这样,手机和电脑的所有应用流量都进行截取,然后从而进行被动搜集,当然还有很多想法,这里就随便举举例子。
搜集完成之后,我们就需要对子域名字典数据进行清洗,那么需要根据域名定义的规则来清洗
1.对于每一级域名长度的限制是63个字符,域名总长度则不能超过253个字符(当每个标签使用单个字符时,限制为127个级别:127个字符加126个点的总长度为253,127*126个点=253 a.b.c.d.e······example.com不能超过253)
2.域名中不进行大小写的区分
3.-和.符号不能单独出现,不能放在开头和结尾
4.域名中不能使用空格及特殊符号!$&?等,域名由一个或多个标签组成,每个标签由一组ASCII字母,数字和连字符(az,AZ,0-9,-)组成
原始字典数据:https://github.com/dwyl/english-words https://www.wordfrequency.info/samples.asp
根据域名定义的规则简单造了脚本:https://github.com/YoungRichOG/HVV/blob/main/Subdomains/handle_dict.py